This is the first Tygron R&D blog entry. With this new blog I will try to explain the more technical challenges inside the Tygron Platform’s Supercomputer.
Most of the Tygron Simulation models (e.g. flooding, subsidence, heat-stress) work by rasterizing GEO data (polygons of buildings, terrains, areas, etc) into grid cells. These grid cells then be used in the simulation models in a very efficient way and the results can be visualized as an overlay.
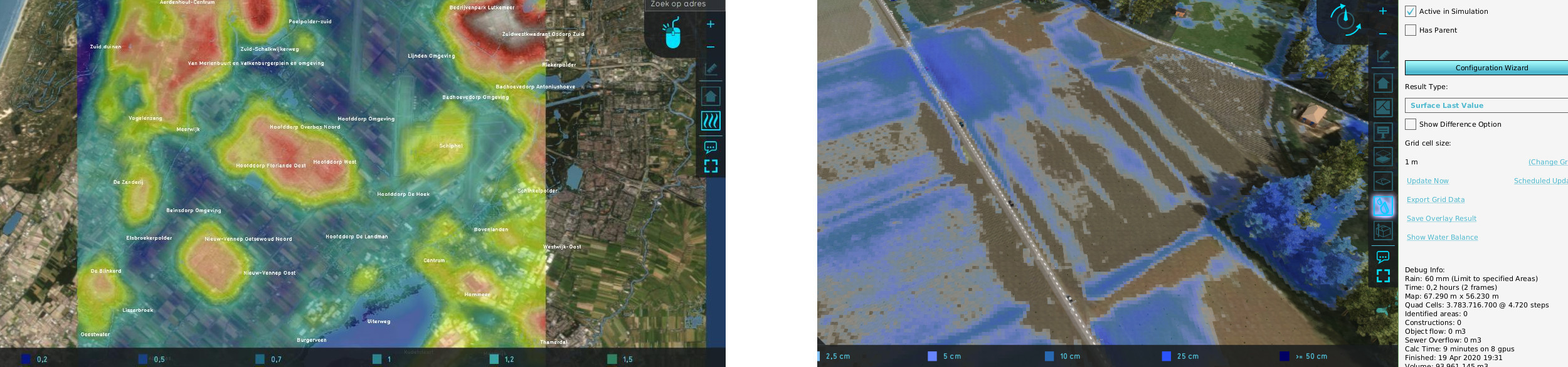
Left: Heat Stress calculation Right: 4 billion grid cell water calculation on 60x60km map
For a simulation to become accurate enough you need small grid cells, e.g. when a waterway is 2 meters wide you cannot use a grid-cell that is 10×10 meters, that would effectively average out the waterway. Typically a grid-cell size between 0,5m – 2m is enough for most GEO based simulations.
On the other hand you also want to perform calculations on a large area. For example, a calculation of a flooding running for many kilometers, or heat stress impact calculations for a hot summer day for multiple cities in a single run.
These two requests combined drive the ever growing need for more grid cells in our simulation models. To facilitate future expansions, we have updated our GPU backbone last weekend to tackle some of the challenges when up scaling from 1 billion (1.000.000.000) grids cells in the current LTS release to 4 billion and beyond.
- Addressing: The Tygron Platform is developed in Java and unlike C arrays are defined using 32 bit signed integers. Since 1 bit is lost to signed (plus or minus) 2^31 can be used, resulting in a max array length of approx 2 billion. To overcome this we are no longer using arrays but matrices instead to store the grid data. The simulation code is written in CUDA (a C derivative from NVIDIA) and there we switched to using unsigned integers, allowing simulations with 4 billion grid cells.
- Memory: Next challenge is memory usage. Most simulation models use multiple variables per grid cell. For example a hydrogical simulation has variables such as water height, flux x, flux y, roughness values, infiltration speeds, terrain height, etc. When you combine that with having 4 billion grid cells and requiring double precision accuracy, you would need 2^32 * 64 bit = 32GB just to represent the water height for each grid cell. So for each variable we will ask ourselves: Do we need it? If so, can it be derived from other used values? Or when it is a simple constant like the land roughness value (typically a value between 0-10 max), can it be stored using just 16 bits?

Left: different precision floating point values Right: Typical 8 GPU node cluster - Locatie: A typical GPU cluster used by Tygron uses eight NVLINK connected NVIDIA V100 Tesla GPUs with 32GB of High Bandwidth Memory. Each V100 has 5120 cores that can calculate lots of data in parallel. However getting the data in the right place it often a bigger challenge. 32GB memory per GPU node seems a lot, but as explained above only a single variable would fill the memory. Therefor you need to efficiently split the data over all nodes resulting in 8×32 = 256GB total or even more when you leave is partly in main memory. To address this Tygron developed a Hybrid Memory System where the Java matrix is automatically splits the data over the available nodes. Per node; part of the memory is local and a border margin is shared with others using CUDA Unified Memory.
- Java: To facilitate rapid development we have developed our own Java2CUDA compiler, which allows us to run the same code in the JVM and on the GPU. Obviously, the GPU performance will be much better (see video below). However, by having a near identical setup in Java makes it easier for us to develop and debug new features and integrate it in to our existing unit tests. Daily thousands of test suites run using both Java and GPU implementation. Note that you need to disable FMA (multiply and add) instruction on the GPU to prevent small round off error compared to Java code that does not have a single operation for “multiply and add”.
- Azul: Using Java as our primary development language has many advantages. However garbage collection (cleaning up old unused data) becomes a big problem when working with large 4 billion cell grids. During rasterization the total memory usage for a single project can become up to ½ TB of RAM and when the default Java garbage collectors kicks in the system could freeze for several minutes! To counter this, the Tygron Platform recycles much of it large matrices/arrays, reusing an old objects prevents them from being collected. However this was still not enough and the solution was found in a California based company called Azul. Using Zing, their specialized, high performance virtual machine, reduces the garbage collection freezes to bare milliseconds.
So far we have only scratched the surface and each challenge above has many more things that can be explained. When you are interested in more details, please let me know (email: maxim at tygron dot com), as it may become the next blog entry.
Regards,
Maxim Knepfle
CTO Tygron